

目录
快速导航-
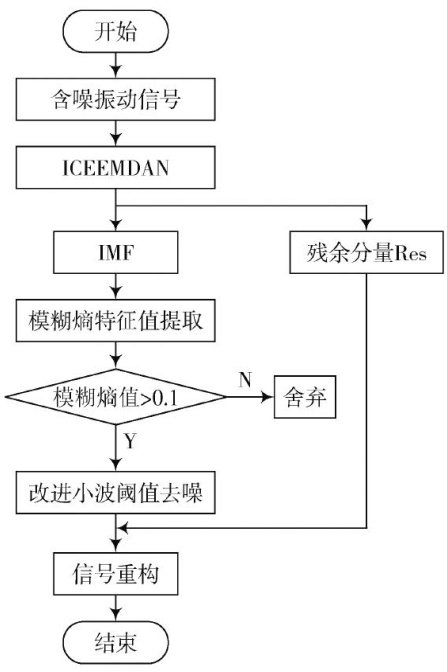
信号分析与图像处理 | ICEEMDAN-FE联合改进小波阀值的振动信号去噪算法
信号分析与图像处理 | ICEEMDAN-FE联合改进小波阀值的振动信号去噪算法
-
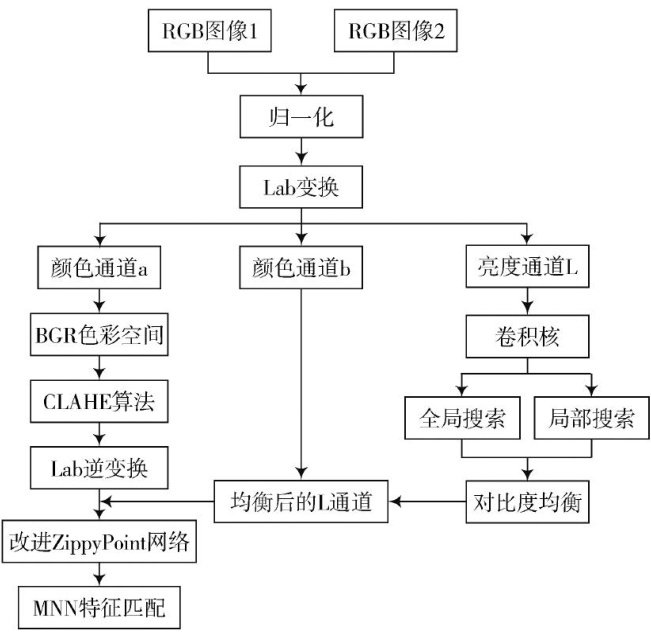
信号分析与图像处理 | 一种基于量化神经网络的SLAM增强型点特征匹配方法
信号分析与图像处理 | 一种基于量化神经网络的SLAM增强型点特征匹配方法
-
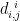
信号分析与图像处理 | 基于Fisher-ISSA-BiLSTM的酗酒脑电信号分类研究
信号分析与图像处理 | 基于Fisher-ISSA-BiLSTM的酗酒脑电信号分类研究
-
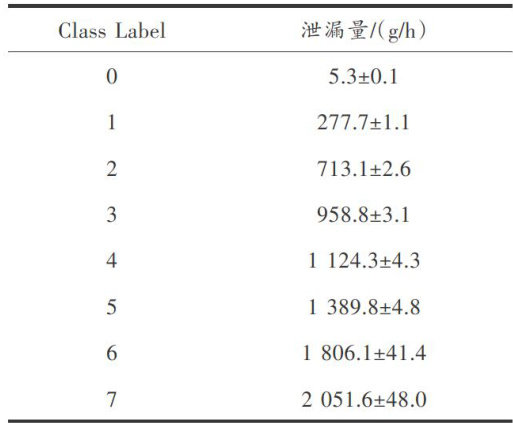
信号分析与图像处理 | 基于改进YOLOv5s的甲烷气体泄漏红外热成像检测方法
信号分析与图像处理 | 基于改进YOLOv5s的甲烷气体泄漏红外热成像检测方法
-
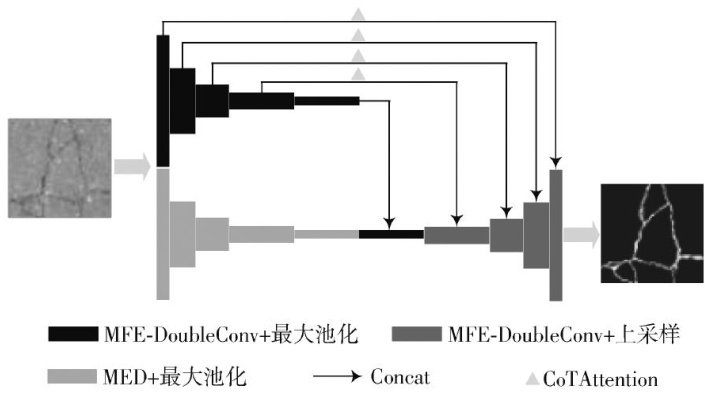
信号分析与图像处理 | DCM-Net:用于复杂环境下的道路裂缝分割算法
信号分析与图像处理 | DCM-Net:用于复杂环境下的道路裂缝分割算法
-

信号分析与图像处理 | 基于YOLOv5n-BGF的雾天道路自标检测算法
信号分析与图像处理 | 基于YOLOv5n-BGF的雾天道路自标检测算法
-
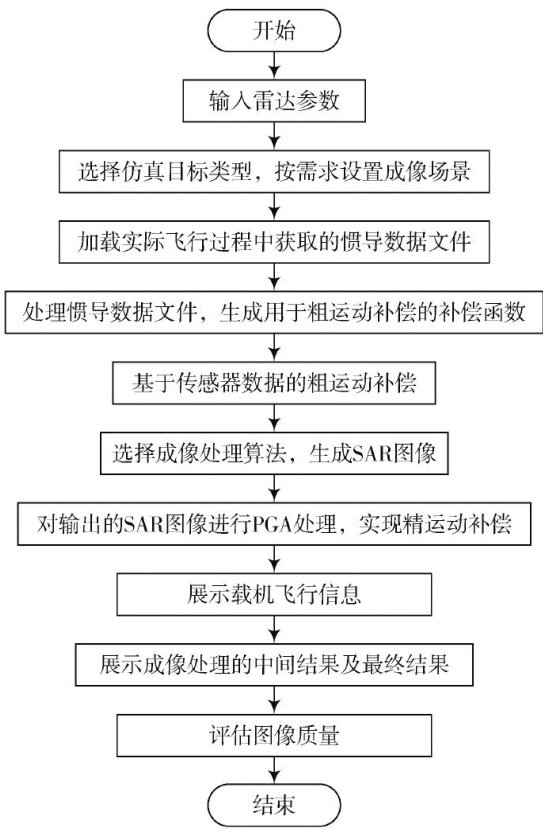
通信与信息工程 | 基于实测惯导数据的机载SAR仿真平台设计与应用
通信与信息工程 | 基于实测惯导数据的机载SAR仿真平台设计与应用
-
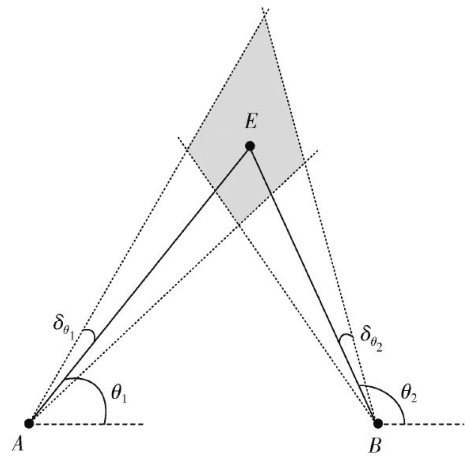
通信与信息工程 | 多站测向交叉定位的定位精度研究
通信与信息工程 | 多站测向交叉定位的定位精度研究
-
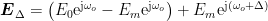
通信与信息工程 | 基于旋转矢量法的快速发射阵相位校准方法研究
通信与信息工程 | 基于旋转矢量法的快速发射阵相位校准方法研究
-
通信与信息工程 | 高移动场景下大规模机器类通信中频率偏移和活跃用户的联合估计算法
通信与信息工程 | 高移动场景下大规模机器类通信中频率偏移和活跃用户的联合估计算法
-
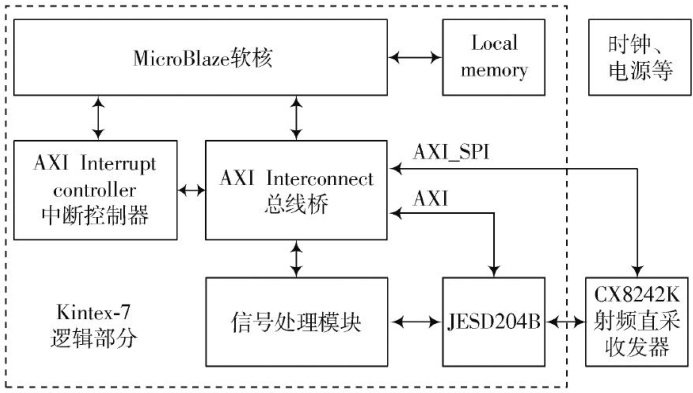
通信与信息工程 | 基于软件无线电的OFDM通信系统设计与实现
通信与信息工程 | 基于软件无线电的OFDM通信系统设计与实现
-
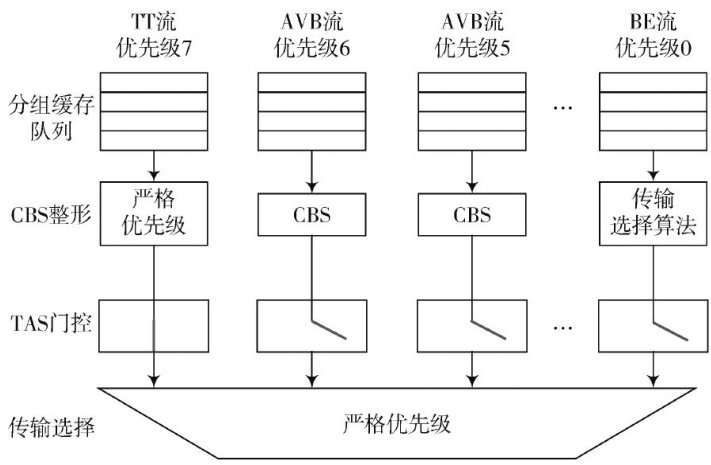
网络与信息安全 | 基于PerDQN的时间敏感网络保护带调度算法
网络与信息安全 | 基于PerDQN的时间敏感网络保护带调度算法
-
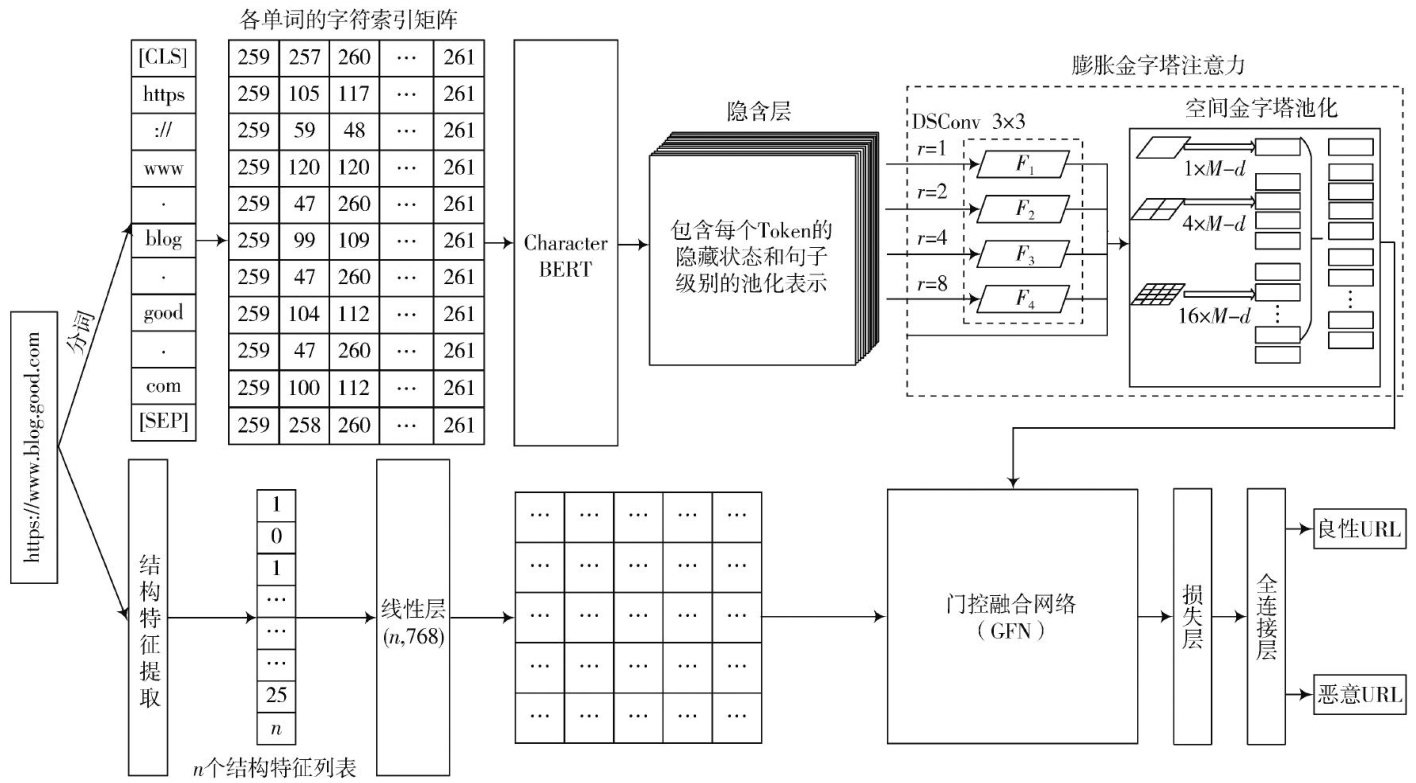
网络与信息安全 | 基于CharacterBERT的恶意URL检测模型
网络与信息安全 | 基于CharacterBERT的恶意URL检测模型
-

网络与信息安全 | 基于部分卷积的残差特征聚合轻量超分辨率网络
网络与信息安全 | 基于部分卷积的残差特征聚合轻量超分辨率网络
-
网络与信息安全 | 基于自适应联邦聚合的分层梯度裁剪算法研究
网络与信息安全 | 基于自适应联邦聚合的分层梯度裁剪算法研究
-
网络与信息安全 | 多分支平滑空洞卷积的无线通信网络节点近邻人侵预警
网络与信息安全 | 多分支平滑空洞卷积的无线通信网络节点近邻人侵预警
-
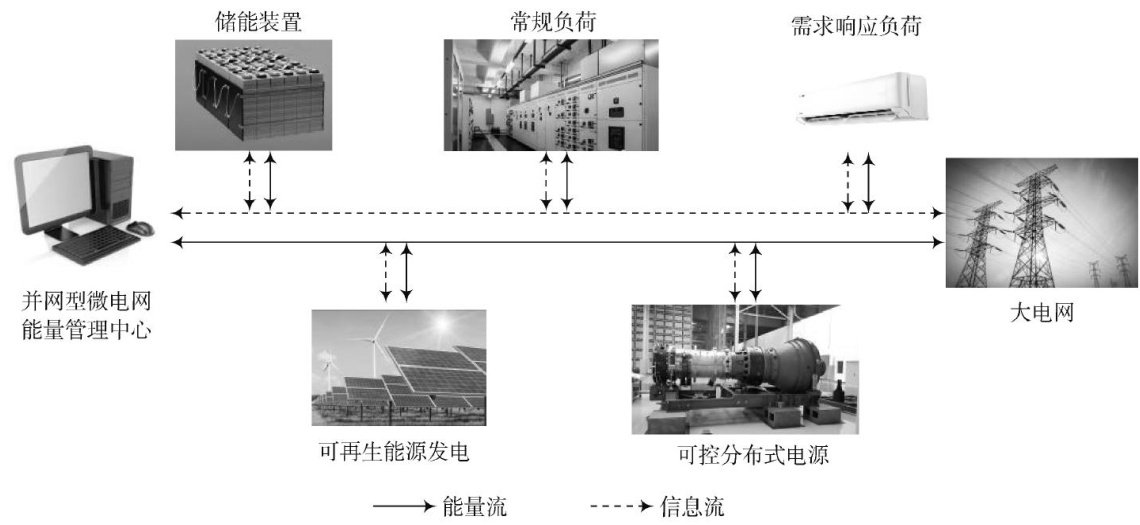
能源与环境科学 | 基于多样性场景性能的微电网鲁棒经济优化算法
能源与环境科学 | 基于多样性场景性能的微电网鲁棒经济优化算法
-

测控与自动化技术 | 基于区域聚焦注意力的多模态方面级情感分析
测控与自动化技术 | 基于区域聚焦注意力的多模态方面级情感分析
-
测控与自动化技术 | 结合注意力机制与边缘感知蒸馏的自监督单目深度估计
测控与自动化技术 | 结合注意力机制与边缘感知蒸馏的自监督单目深度估计
-

测控与自动化技术 | 基于改进APF-RRT*算法的机械臂路径规划研究
测控与自动化技术 | 基于改进APF-RRT*算法的机械臂路径规划研究
-
测控与自动化技术 | 基于等角映射的高维不平衡数据增量式降维算法
测控与自动化技术 | 基于等角映射的高维不平衡数据增量式降维算法
-
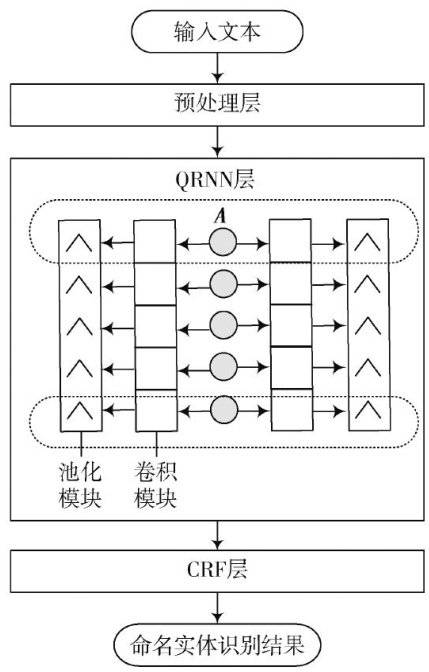
测控与自动化技术 | 自然语言处理下并行化命名实体识别
测控与自动化技术 | 自然语言处理下并行化命名实体识别
-
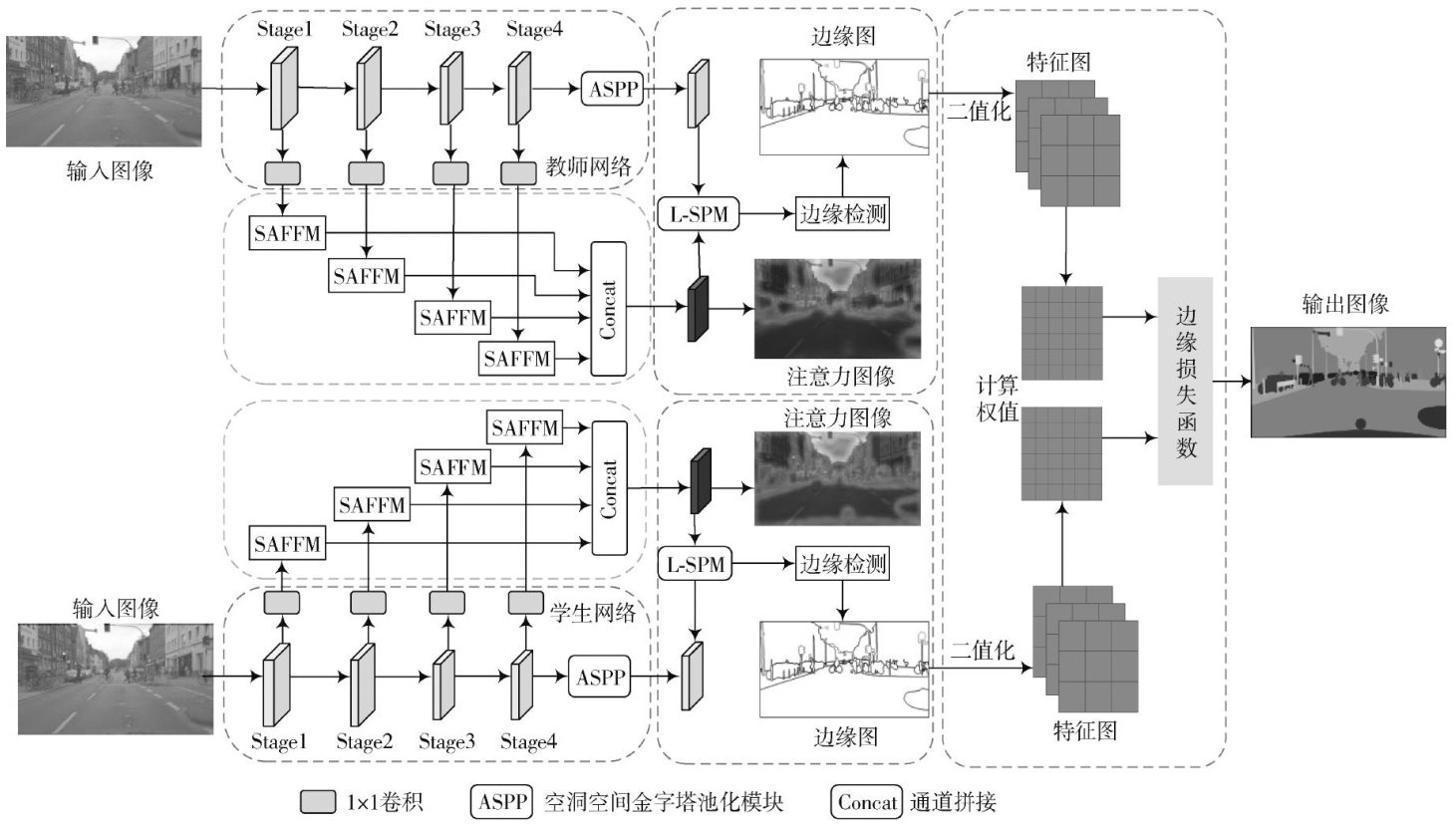
电子技术及应用 | 形状感知引导边缘结构化的知识蒸馏语义分割算法
电子技术及应用 | 形状感知引导边缘结构化的知识蒸馏语义分割算法
-
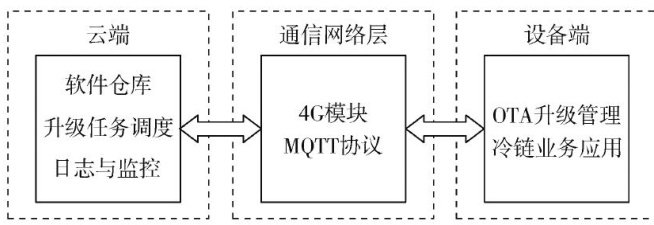
电子技术及应用 | 基于Bsdiff的冷链物流OTA升级技术研究
电子技术及应用 | 基于Bsdiff的冷链物流OTA升级技术研究
-
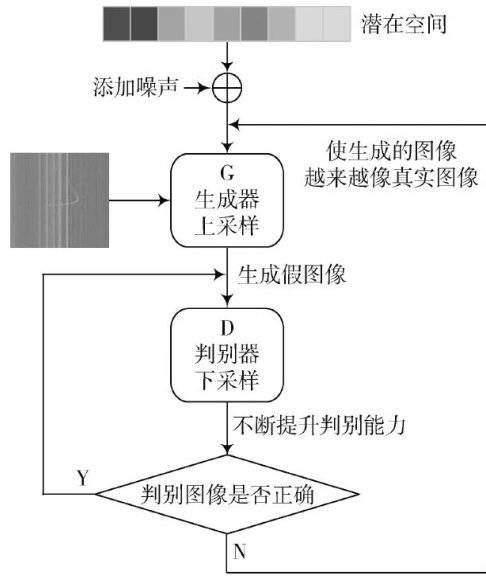
电子技术及应用 | 基于改进DCGAN的斜测电离图数据增强算法
电子技术及应用 | 基于改进DCGAN的斜测电离图数据增强算法
-
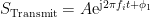
电子技术及应用 | 基于迁移学习的多载波相位差位移估计方法
电子技术及应用 | 基于迁移学习的多载波相位差位移估计方法
-

电子技术及应用 | 基于多尺度注意力与双流融合特征的微表情识别
电子技术及应用 | 基于多尺度注意力与双流融合特征的微表情识别
-
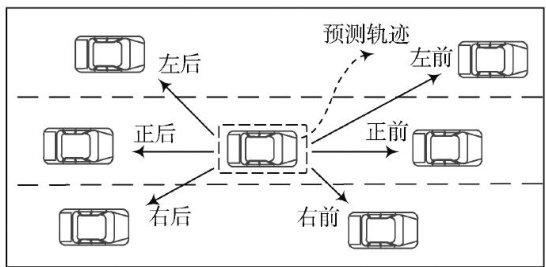
智能交通与导航 | 基于时空趋势感知多头自注意力的LSTM车辆轨迹预测
智能交通与导航 | 基于时空趋势感知多头自注意力的LSTM车辆轨迹预测
-
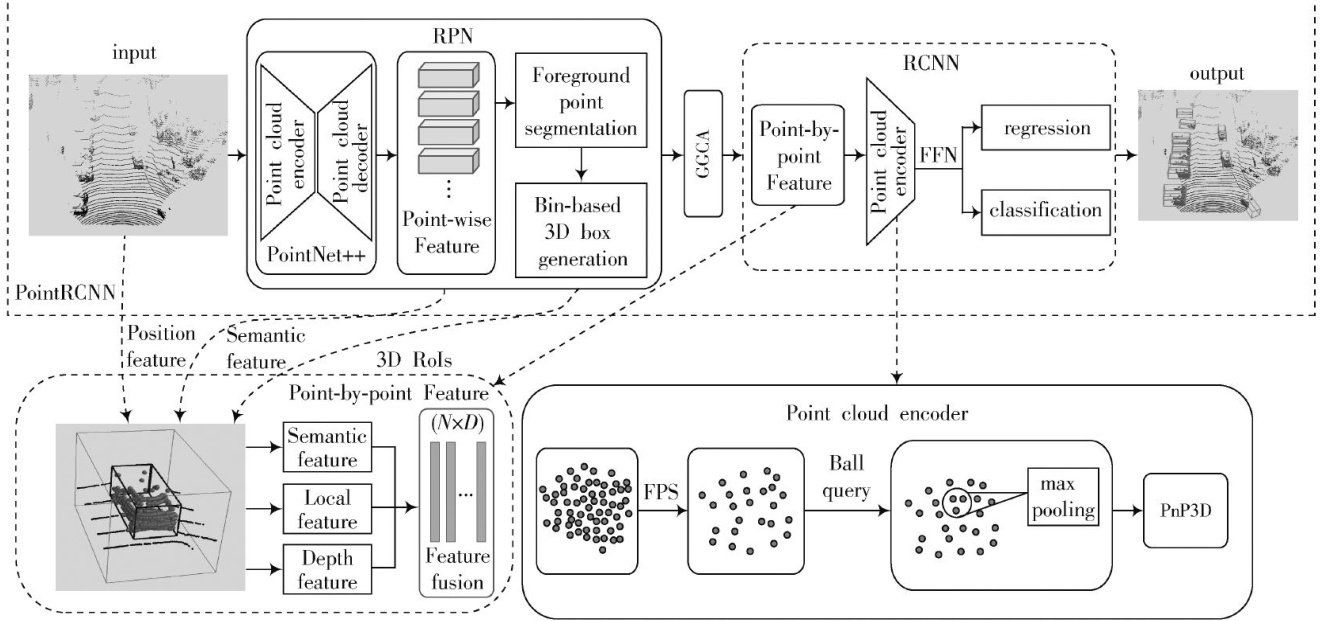
智能交通与导航 | 基于3DGP-PointRCNN的道路场景三维点云小目标检测
智能交通与导航 | 基于3DGP-PointRCNN的道路场景三维点云小目标检测
 、RMSE ,=4.417 和 δ?1=0.894 的性能,能够成功抑制深度图的边缘伪影,优于目前主流方法。
、RMSE ,=4.417 和 δ?1=0.894 的性能,能够成功抑制深度图的边缘伪影,优于目前主流方法。

















 登录
登录